本文共 9321 字,大约阅读时间需要 31 分钟。
一 MHA
1.1 关于MHA
MHA(master HA)是一款开源的MySQL的高可用程序,它为MySQL的主从复制架构提供了automating master failover功能。MHA在监控到的master节点故障时,会提升其中拥有最新数据的slave节点成为新的master节点,在此期间,MHA会通过熊其它节点获取额外信息来源避免一致性方面的问题。MHA还提供了master节点的在线切换功能,即按需切换master/slave节点。
MHA服务有两种角色,MHA Manager(管理节点)和MHA Node(数据节点):
MHA Manager:通常单独部署在一台独立机器上管理多个master/slave集群,每个master/slave集群称作一个application; MHA node:运行在每台MySQL服务器上(master/slave/manager),它通过监控具备解析和清理logs功能的脚本来加快故障转义。Manager package:Can manager multiple {master,slaves} pairs
masterha_manager:Automated master monitoring and failover command Other helper scripts:Manual master failover,online master switch,con checking,etcNode package :Deplpying on all MySQLservers save_binary_logs:Copying master's binary logs if accessible apply_diff relay_logs:Generating differential relay logs from the latest slave,and applying all differential binlog events purge_relay_logs:Deleting relay logs withotu stopong SQL thread拓扑图
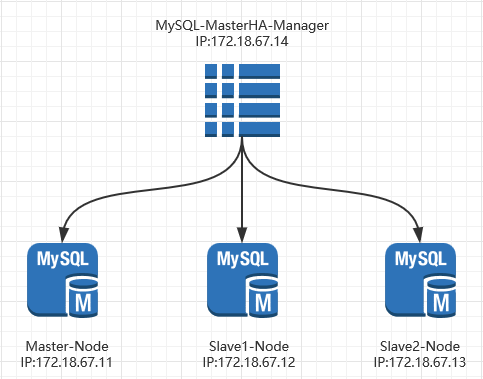
1.2 Architecture of MHA
MySQL复制集群中的master故障时,MHA按如下步骤进行故障转移:
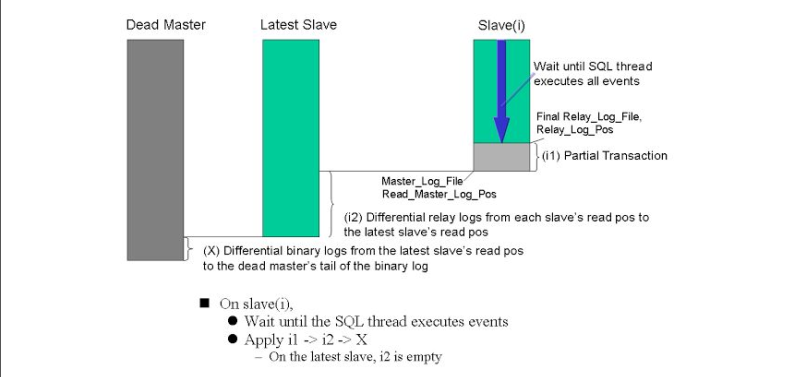
1.3 MHA组件
MHA会提供诸多工具程序。其常见如下所示:
Manager角色拥有的工具
masterha_check_ssh:MHA 依赖的 SSH 环境检测工具 masterha_check_repl:MySQL 复制环境检测工具 masterha_manager:MHA 服务主程序 masterha_check_status:MHA 运行状态探测工具 masterha_master_monitor:MySQL master 节点可用性监测工具; – masterha_master_switch:master 节点切换工具 masterha_conf_host:添加或删除配置的节点 masterha_stop:关闭 MHA 服务的工具Node节点的拥有的工具 save_binary_logs:保存和复制 master 的二进制日志 apply_diff_relay_logs:识别差异的中继日志事件并应用于其它 slave filter_mysqlbinlog:去除不必要的 ROLLBACK 事件(MHA 已不再使用这个工具): – purge_relay_logs:清除中继日志(不会阻塞 SQL 线程)自定义扩展工具 secondary_check_script:通过多条网络路由检测 master 的可用性 master_ip_failover_script:更新 application 使用的 masterip; – shutdown_script:强制关闭 master 节点 report_script:发送报告 init_conf_load_script:加载初始配置参数 master_ip_online_change_script:更新 master 节点 ip 地址二 准备MySQL Replication环境
2.1 配置主从复制文件
MAH对MySQL复制环境有特殊要求,例如各节点都要开启二进制日志和中继日志,各从节点必须显式启用其read-only属性,并关闭relay-log-purge功能等,这里先对其配置做实现说明。
本实验环境共有四个节点,其角色分配如下:
node1:MariaDB masternode2:MariaDB slavenode3:MariaDB slavenode4:MHA Manager#各节点的etc/hosts文件配置内容如下:172.18.67.11 node1 node1172.18.67.12 node2 node2172.18.67.13 node3 node3172.18.67.14 node4 node4
#初始节点master的配置:server_id=1relay_log=relay-loglog_bin=master-log#所有slave节点的配置如下:server_id=2,3 #两个slave节点id号不同relay_log=relay-loglog_bin=master-logrelay_log_purge=0read_only=1
2.2 配置主从架构
#启动MariaDB服务[root@node1 ~]# systemctl start mariadb[root@node2 ~]# systemctl start mariadb[root@node3 ~]# systemctl start mariadb#登入主节点[root@node1 ~]# mysqlMariaDB [(none)]> SHOW MASTER STATUS;+-------------------+----------+--------------+------------------+| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |+-------------------+----------+--------------+------------------+| master-log.000003 | 245 | | |+-------------------+----------+--------------+------------------+#为一个用户授权MariaDB [(none)]> GRANT REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO 'repluser'@'172.18.67.%' IDENTIFIED BY 'replpass';MariaDB [(none)]> FLUSH PRIVILEGES;#从节点node2配置MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='172.18.67.11',MASTER_USER='repluser',MASTER_PASSWORD='replpass',MASTER_LOG_FILE='master-log.000003',MASTER_LOG_POS=245;MariaDB [(none)]> START SLAVE;MariaDB [(none)]> SHOW SLAVE STATUS\G;*************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 172.18.67.11 Master_User: repluser Master_Port: 3306 Connect_Retry: 60 Master_Log_File: master-log.000003 Read_Master_Log_Pos: 497 Relay_Log_File: relay-log.000002 Relay_Log_Pos: 782 Relay_Master_Log_File: master-log.000003 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 497 Relay_Log_Space: 1070 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 1#从节点node3配置MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='172.18.67.11',MASTER_USER='repluser',MASTER_PASSWORD='replpass',MASTER_LOG_FILE='master-log.000003',MASTER_LOG_POS=245;MariaDB [(none)]> START SLAVE;MariaDB [(none)]> SHOW SLAVE STATUS\G;*************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 172.18.67.11 Master_User: repluser Master_Port: 3306 Connect_Retry: 60 Master_Log_File: master-log.000003 Read_Master_Log_Pos: 497 Relay_Log_File: relay-log.000002 Relay_Log_Pos: 782 Relay_Master_Log_File: master-log.000003 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 497 Relay_Log_Space: 1070 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 1MariaDB [(none)]> SELECT User,Host FROM mysql.user;+----------+-------------+| User | Host |+----------+-------------+| root | 127.0.0.1 || repluser | 172.18.67.% || root | ::1 || | localhost || root | localhost || | node3 || root | node3 |+----------+-------------+#在主节点授权一个HA管理的账号MariaDB [(none)]> GRANT ALL ON *.* TO 'haadmin'@'172.18.67.%' IDENTIFIED BY 'hapass';MariaDB [(none)]> FLUSH PRIVILEGES;
三 安装MHA及配置
3.1 准备基于ssh互信通信环境
MHA集群中的各节点彼此之间均需要基于ssh互信互通,以实现远程控制及数据管理功能。简单起见,可在Manager节点生成密钥对儿,并设置其可远程连接本地主机后,将私钥文件及authorized_keys文件复制给余下的所有节点即可。
#下面的操作在manager节点操作即可[root@node4 ~]# ssh-keygen -t rsa[root@node4 ~]# cat .ssh/id_rsa.pub > .ssh/authorized_keys[root@node4 ~]# chmod 600 .ssh/authorized_keys[root@node4 ~]# scp -p .{id_rsa,authorized_keys} root@node1:/root/.ssh/[root@node4 ~]# scp -p .{id_rsa,authorized_keys} root@node2:/root/.ssh/[root@node4 ~]# scp -p .{id_rsa,authorized_keys} root@node3:/root/.ssh
3.2 安装MHA
下载:
mha4mysql-manager-0.56-0.el6.noarch.rpmmha4mysql-node-0.56-0.el6.noarch.rpm#在MHA节点安装两个包[root@node4 ~]# yum install ./mha4mysql-*#将mha4mysql-node-0.56-0.el6.noarch.rpm复制到其它三个节点[root@node4 ~]# for i in {1..3};do scp mha4mysql-node-0.56-0.el6.noarch.rpm node${i}:/root/; done#安装mha4mysql-node-0.56-0.el6.noarch.rpm[root@node4 ~]# for i in {1..3};do ssh node$i 'yum install -y /root/mha4mysql-node-0.56-0.el6.noarch.rpm'; done 3.3 初始化MHA
Manager节点需要为每个监控的master/slave集群提供一个专用的配置文件,而所有的master/slave集群也可共享全局配置。全局配置文件默认为/etc/masterha_default.cnf,其为可选配置。如果监控一组master/slave集群,也可直接通过application的配置来提供各服务器的默认配置信息。而每个application的配置文件路径为自定义,例如本示例中将使用/etc/masterha/app1.cnf,其内容如下所示:
[root@node4 ~]# vim /etc/mha4mysql/mha4.cnf[server default]user=mhaadmin password=mhapassmanager_workdir=/data/masterha/app1manager_log=/data/masterha/app1/manager.log remote_workdir=/data/masterha/app1ssh_user=rootrepl_user=repluserrepl_password=replpassping_interval=1master_ip_failover_script=/tmp/master_ip_failover [server1] hostname=172.18.67.11ssh_port=22candidate_master=1 [server2] hostname=172.18.67.12 ssh_port=22 candidate_master=1 [server3] hostname=172.18.67.13 ssh_port=22candidate_master=1#检测各节点间ssh互信互通配置对否成功[root@node4 ~]# masterha_check_ssh --conf=/etc/masterha/app1.cnf[root@node4 ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf#最后一行输出如下类似信心表示成功MySQL Replication Health is OK.#启动MHA[root@node4 ~]# nohup masterha_manager --conf=/etc/masterha/app1.cnf > /data/masterha/app1/manager.log 2>&1 &#查看MHA状态[root@node4 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
3.4 测试故障转移
#停止master节点的mariadb服务。此操作在master节点执行[root@node1 ~]# systemctl stop mariadb #查看MHA状态。此操作在manager节点执行[root@node4 ~]# masterha_check_status --conf=/etc/mha/app1.cnfapp1 is stopped(2:NOT_RUNNING) #验证master节点是否切换。此操作在slave节点上执行。#可以看到slave2节点的Master_Host已经从172.18.67.11切换到172.18.67.12[root@node2 ~]# mysql -e 'SHOW SLAVE STATUS\G' | grep "Master_Host" Master_Host: 172.18.67.12
转载地址:http://pqnna.baihongyu.com/